AWS Data Processing
Built a distributed data processing environment on AWS EC2 using Hadoop ecosystem to understand cluster architecture, data flow, and large-scale processing systems.
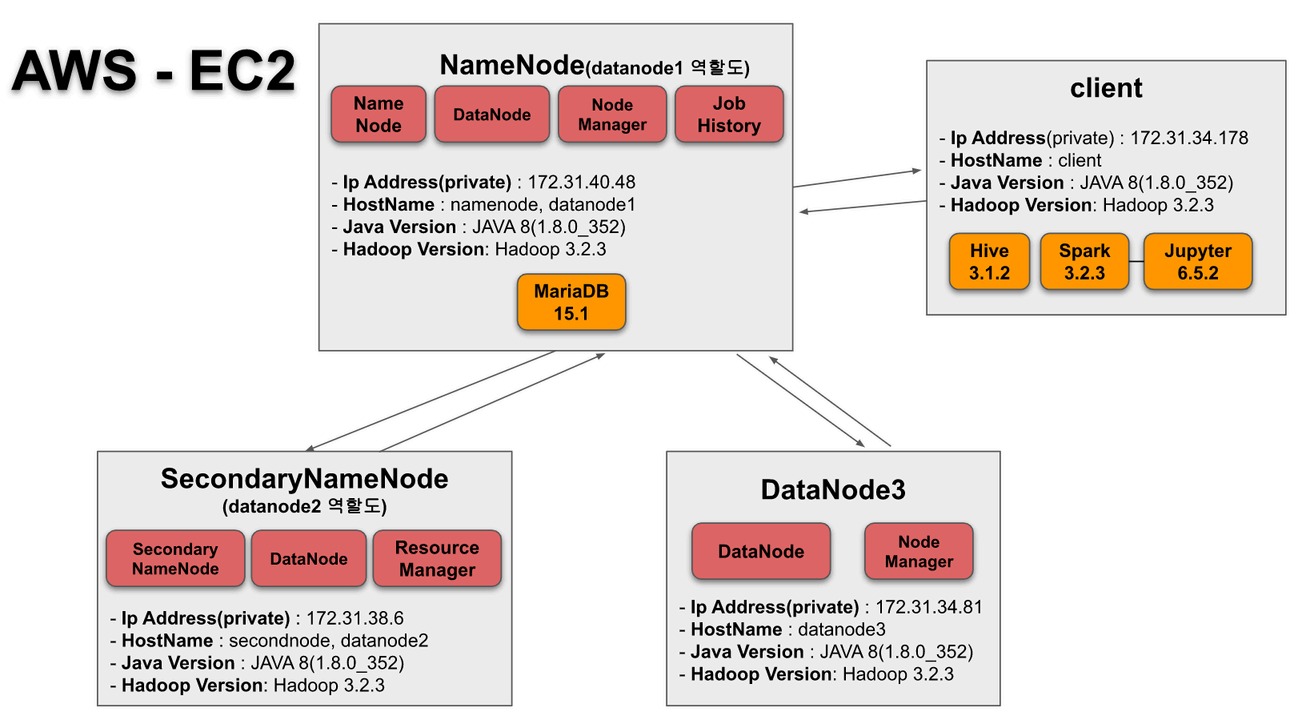
Overview
This project focused on understanding distributed computing systems by building a Hadoop-based data processing environment on AWS. It provided hands-on experience with cluster setup, data storage, and processing workflows.
Architecture
The system was deployed on AWS EC2 instances, forming a distributed cluster. Hadoop handled data storage, Hive provided querying capability, and Spark was used for data processing tasks.
What I Built
- Configured Hadoop cluster across multiple EC2 instances
- Set up Hive for structured data querying
- Implemented Spark jobs for data processing
- Managed cluster communication and metadata
- Tested distributed data workflows
Challenges & Solutions
The main challenge was understanding and managing distributed system behavior across multiple nodes.
-
Challenge: Cluster configuration complexity.
Solution: Carefully configured node roles and communication. -
Challenge: Data consistency across distributed environment.
Solution: Used Hadoop HDFS and metadata management. -
Challenge: Processing large data efficiently.
Solution: Leveraged Spark for distributed computation.
Result
This project improved my understanding of distributed systems, cluster-based architecture, and large-scale data processing workflows in cloud environments.